Journal Information
Title: Enfoque UTE
Abbreviated Title: Enfoque UTE
ISSN (print): 1390-9363
ISSN (electronic): 1390-6542
Publisher: Universidad UTE (Quito, Ecuador)

El proceso de toma de decisiones se puede distinguir de tres maneras: a largo, mediano y corto plazo. A largo plazo, decisiones estratégicas en el ámbito productivo, por ejemplo, podrían ser la determinación de cuántas máquinas se deben comprar o qué productos se pueden ofrecer al mercado. La aceptación de pedidos de clientes o planificación de personal constituyen ejemplos de decisiones a mediano plazo. Sin embargo, una decisión a corto plazo, que es el tipo de decisión que más comúnmente es realizada en un entorno real de la producción sería: en qué momento y sobre cuáles máquinas se debe procesar un conjunto de tareas.
Un problema de secuenciación de tareas o problema de scheduling, como también se le conoce por su palabra en el idioma inglés, es precisamente esto: un proceso de asignación de tareas a un conjunto limitado de recursos disponibles en un intervalo de tiempo, donde determinados criterios son optimizados (Fonseca, Martínez, Bermúdez et al., 2015; Pinedo, 2008)
De esta forma, la secuenciación de tareas está directamente asociada con la ejecutabilidad y optimalidad de un plan prestablecido y puede ser encontrada en una amplia gama de aplicaciones, tales como: programación de despacho de vuelos en los aeropuertos, programación de líneas de producción de una fábrica, programación de cirugías en un hospital, reparación de equipos o maquinarias en un taller, entre otros (Fonseca, Martínez, Figueredo et al., 2014; Toro, Restrepo, y Granada, 2006)
En muchas ocasiones, la cadena de producción estructurada para la secuenciación de procesos requiere que cada una de las tareas a ejecutar transite por todas las etapas productivas en el mismo orden. Este problema es conocido de forma general como Variante de Flujo Regular o Flow Shop Scheduling Problem (FSSP), el cual, como muchos otros en este campo, son de difícil solución y están clasificados técnicamente como de solución en un tiempo no polinomial (NP-Hard)
De forma general, desde la década del 50, científicos en el área de la Investigación de Operaciones (IO) se apoyan en métodos matemáticos de optimización para problemas de scheduling contribuyendo con una variedad amplia de metodologías en las que se incluyen la programación lineal
La mayoría de los métodos descritos anteriormente, garantizan, en muchos de los casos, soluciones óptimas que son logradas en un período razonable; sin embargo, de forma general, estas excluyen situaciones que se presentan en la práctica industrial. Desafortunadamente, los problemas de scheduling en el mundo real, al presentar un conjunto de restricciones propias de estos entornos, se convierten en problemas mucho más desafiantes, dificultando, en muchos casos, la aplicabilidad de dichos métodos (Ruiz, Sivrikaya, y Urlings, 2008)
El modelado es un tema a considerar al solucionar problemas de scheduling en un entorno real. Los innumerables tipos de procesos de fabricación, cada uno con sus propias particularidades, hacen difícil construir modelos generalmente aplicables. Algunas restricciones son difíciles de representar matemáticamente. Además, encontrar las restricciones correctas para modelar la realidad depende sobre todo del conocimiento extenso del dominio, que puede ser inasequible para los investigadores y que es solamente utilizable para un tipo particular de proceso de producción. Entre estas se pueden encontrar las siguientes:
Fechas de liberación de las máquinas: En las empresas manufactureras antes de comenzar el proceso productivo, las máquinas son configuradas inicialmente según el tipo de trabajo que pueden realizar.
Tiempos de configuración dependientes de la secuencia: Las operaciones de cambio de referencia en las máquinas varían constantemente. Estas se demoran más cuando el trabajo entrante es muy diferente al saliente, impactando el desempeño total de las operaciones.
Tiempos de transportación: Los trabajos necesitan de un intervalo de tiempo para ser transportados de una máquina a otra.
Todo esto da lugar a que en las empresas se tenga que revisar la política de generar buenas programaciones de la producción. A su vez, refuerza la necesidad de automatizar el modelado de problemas aplicando algoritmos que puedan adaptarse a las características de un entorno real. Todo lo anteriormente planteado ilustra la necesidad de investigar otras estrategias, así como nuevos y eficientes algoritmos para resolver el problema en cuestión.
Por tal motivo, en este trabajo se presenta una propuesta de un Algoritmo Genético Híbrido el cual es combinado con una Búsqueda Local de Vecindad Variable para la solución del FSSP bajo el efecto de un conjunto de restricciones que se presentan con frecuencia en entornos manufactureros reales. El algoritmo propuesto es probado con varias instancias del problema mostrando que el mismo alcanza excelentes soluciones comparables con las óptimas.
En esta sección se realiza una formalización del problema de secuenciación de tareas que se aborda en esta investigación, se introducen los Algoritmos Genéticos como metodología computacional para la solución de problemas de optimización, y por último, se diseña la metaheurística híbrida propuesta que es empleada para la solución del problema tratado.
Dentro de la teoría de scheduling se puede distinguir un gran número de problemas. En estos se tiene un conjunto de N trabajos que han de ser procesados sobre un conjunto de M recursos o máquinas físicas siguiendo un patrón de flujo o ruta tecnológica (Mehmet y Betul, 2014; Seido Naganoa, Almeida da Silva, y Nogueira Lorena, 2012)Con frecuencia, estos procesamientos deben ser ejecutados para todos los trabajos en el mismo orden, implicando que estos sigan el mismo patrón de flujo, como ocurre en diversos ambientes reales de manufactura. Este problema es referido como Variante de Flujo Regular o FSSP
Solo se cuenta con una máquina-herramienta de cada tipo por etapa.
Las restricciones tecnológicas están bien definidas y son previamente conocidas, además que son inviolables.
No está permitido que dos operaciones del mismo trabajo se procesen simultáneamente.
Ningún trabajo puede ser procesado más de una vez en la misma máquina.
Cada trabajo es procesado hasta concluirse, una vez que se inicia una operación esta se interrumpe solamente cuando se concluye.
Ninguna máquina puede procesar más de un trabajo a la vez.
Se tienen en cuenta las fechas de liberación de las máquinas.
Los tiempos de configuración dependientes de la secuencia se conocen de antemano.
El tiempo de transportación de los trabajos entre etapas es considerado.
El objetivo es encontrar una secuencia de trabajos por etapas bajo la restricción que el procesamiento de cada trabajo tiene que ser continuo con respecto al objetivo de minimizar el makespan o 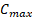 como también se le conoce
.
Por lo tanto:
como también se le conoce
.
Por lo tanto:
Si tenemos a 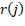 como el tiempo de liberación de la máquina
como el tiempo de liberación de la máquina 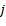 ,
, 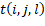 como el tiempo de transportación del trabajo
como el tiempo de transportación del trabajo 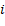 desde la máquina a la máquina
desde la máquina a la máquina 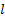 ,
,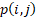 como el tiempo de procesamiento del trabajo en la máquina ,
como el tiempo de procesamiento del trabajo en la máquina , 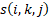 como el tiempo de configuración dependiente de la secuencia entre el trabajo y el trabajo
como el tiempo de configuración dependiente de la secuencia entre el trabajo y el trabajo 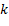 en la máquina , y una permutación de trabajos
en la máquina , y una permutación de trabajos 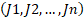 , entonces calculamos el tiempo de completamiento total denotado por como sigue:
, entonces calculamos el tiempo de completamiento total denotado por como sigue:


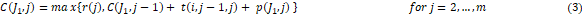
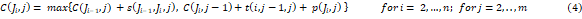

Bajo estas condiciones, el tiempo de procesamiento total corresponde al tiempo de culminación de procesamiento del último trabajo en la última máquina. En otras palabras, es el tiempo necesario para completar todos los trabajos (Fonseca et al., 2015)
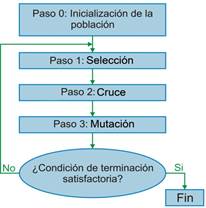
Los Algoritmos Genéticos (AGs), introducidos por Holland (Holland, 1975). La Figura 1 muestra la estructura básica de un AG.
La Figura 1 recoge los pasos fundamentales de un AG. Se inicializa la población aleatoriamente y se evalúan los individuos de la población. En función de la aptitud de los individuos se seleccionan los padres para ser recombinados. El proceso de recombinación tiene como objetivo tomar información de varios individuos combinándola en otro, que supuestamente debe ser mejor. Durante la alteración del material genético, la mutación se realiza una exploración en una vecindad del individuo a mutar. Los criterios de parada involucran generalmente ideas relacionadas con la convergencia de la población de individuos, el número de generaciones obtenidas por el AG y el número de evaluaciones de la función objetivo.
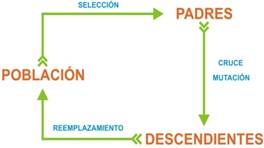
El ciclo de evolución de un AG mostrado en la Figura 2, permite entender de forma sencilla su funcionamiento.
La solución del FSSP bajo el efecto de restricciones reales de la producción utilizando AG, comienza por el diseño de la representación de la solución del problema dado. La representación de las posibles soluciones dentro del espacio de búsqueda de un problema define la estructura del cromosoma que va ser manipulado por el algoritmo. Existen diferentes tipos de representaciones, la elección de cuál usar dependerá siempre de las características del problema a resolver (Márquez, 2012; Yamada, 2003)Fonseca et al. (2014), según la cual el cromosoma representa la secuencia natural en la que se procesan los trabajos. La Figura 3 muestra el cromosoma que representa una solución para el FSSP donde son procesados 8 trabajos. La secuencia de números representa el número del trabajo y el orden en el que serán procesados. La aptitud de cada cromosoma estará dado por el cálculo del C_max a partir de la secuencia de trabajo representada en el mismo.
El flujo de trabajo del Algoritmo Genético Híbrido (AGHVNS) propuesto es presentado a través de un diagrama de bloques en la Figura 4.
Cuando se genera la población inicial (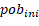 ), el objetivo es adquirir una población diversificada. En el AGHVNS propuesto, la población inicial es generada aleatoriamente y el tamaño es variable en dependencia de la cantidad de trabajos (
), el objetivo es adquirir una población diversificada. En el AGHVNS propuesto, la población inicial es generada aleatoriamente y el tamaño es variable en dependencia de la cantidad de trabajos (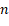 ) y de máquinas (
) y de máquinas (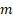 ) donde
) donde 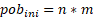 . En el paso 2, un AG básico (ver Figura 1) es empleado para mejorar la población. En nuestra implementación, la selección de padres está basada en el esquema clásico de selección por Ranking donde
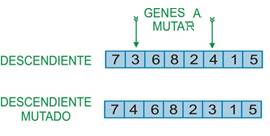
. En el paso 2, un AG básico (ver Figura 1) es empleado para mejorar la población. En nuestra implementación, la selección de padres está basada en el esquema clásico de selección por Ranking donde 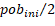 parejas de padres son seleccionadas. Para la selección de cada pareja de padres se van apareando de dos en dos a los cromosomas de mayor a los de menor aptitud. Luego de esto, se realiza el cruzamiento de cada apareamiento. En nuestro caso se aplica el método Dos Punto de Cruce. Es preciso mencionar que al aplicar directamente este método pueden generarse cromosomas ilegales (en nuestro caso significa que en un mismo cromosoma puede estar un trabajo dos veces). Este problema es corregido utilizando la metodología estudiada en (Murata, Ishibuchi, y Tanaka, 1996) la cual está basada en la sustitución del o de los trabajos que se repiten por los que no se encuentran en dicho cromosoma. Luego a la combinación se realizaría el proceso de mutación el cual consiste en seleccionar dos puntos del cromosoma aleatoriamente y cambiar de posición estos trabajos. La Figura 5 muestra este proceso.
parejas de padres son seleccionadas. Para la selección de cada pareja de padres se van apareando de dos en dos a los cromosomas de mayor a los de menor aptitud. Luego de esto, se realiza el cruzamiento de cada apareamiento. En nuestro caso se aplica el método Dos Punto de Cruce. Es preciso mencionar que al aplicar directamente este método pueden generarse cromosomas ilegales (en nuestro caso significa que en un mismo cromosoma puede estar un trabajo dos veces). Este problema es corregido utilizando la metodología estudiada en (Murata, Ishibuchi, y Tanaka, 1996) la cual está basada en la sustitución del o de los trabajos que se repiten por los que no se encuentran en dicho cromosoma. Luego a la combinación se realizaría el proceso de mutación el cual consiste en seleccionar dos puntos del cromosoma aleatoriamente y cambiar de posición estos trabajos. La Figura 5 muestra este proceso.
Ishibuchi, Yoshida, y Murata (2003), enfatizan la importancia del balance entre la búsqueda del AG y la búsqueda local para encontrar soluciones FSSP de alta calidad en tiempos computacionales aceptables. En el paso 3 de nuestro algoritmo, una Búsqueda Local de Vecindad Variable es aplicada para explorar la vecindad de un subconjunto de la población complementando el AG. En cada generación se seleccionan los individuos obtenidos en el paso 2. Esta intensificación opera sobre cada uno de los individuos seleccionados aplicando un operador de vecindad el cual es escogido aleatoriamente. El valor y detalle de cada operador se describe como sigue:
Operador de Intercambio: este funciona de manera similar al operador de mutación.
Operador de traslado o inserción: se selecciona un trabajo aleatoriamente y este se mueve hacia otra posición del cromosoma seleccionada aleatoriamente.
Operador 2-Op: se seleccionan dos trabajos consecutivos aleatoriamente, luego se selecciona una posición aleatoriamente dentro del cromosoma y estos son trasladados hacia esa posición.
No se realiza ninguna operación sobre el cromosoma.
La idea principal detrás de esta intensificación es diversificar la población y lograr un balance entre la exploración y explotación.
Por último, en el paso 4 de nuestro algoritmo, se procede a renovar la población a partir de los nuevos individuos generados. Específicamente, los individuos menos aptos de la población actual son sustituidos por las soluciones obtenidas en la fase de intensificación.
Instancias de problemas FSSP han sido definidas por diferentes autores y ampliamente utilizadas por muchos investigadores en el campo de scheduling para analizar el rendimiento de las metodologías propuestas y comparar sus soluciones contra otros algoritmos. Estas instancias están disponibles en (Beasley, 1990; Taillard, 1993)
Con el objetivo de analizar el rendimiento del algoritmo propuesto, 10 instancias son utilizadas. Si se tiene en cuenta que el espacio de búsqueda para el FSSP es 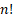 , estas instancias fueron creadas con dimensiones pequeñas con el objetivo de realizar una búsqueda exhaustiva en este espacio para determinar la solución óptima y comparar estos valores con los obtenidos por el AGHVNS. De igual manera, estos resultados son comparados con la variante del AG propuesta en este trabajo excluyendo la fase de intensificación. De esta forma se analiza el efecto de esta fase en la solución del problema.
, estas instancias fueron creadas con dimensiones pequeñas con el objetivo de realizar una búsqueda exhaustiva en este espacio para determinar la solución óptima y comparar estos valores con los obtenidos por el AGHVNS. De igual manera, estos resultados son comparados con la variante del AG propuesta en este trabajo excluyendo la fase de intensificación. De esta forma se analiza el efecto de esta fase en la solución del problema.
La dimensión de estas instancias es: 5x3, 5x4, 5x5, 7x6, 7x7, 8x8, 9x4, 9x9, 10x8 y10x10. Se generaron números aleatorios para crear los tiempos de procesamiento, tiempos de configuración dependientes de la secuencia, fechas de liberación y tiempos de transportación. Cada instancia fue ejecutada 10 veces.
Para determinar la calidad de las soluciones, el Error Relativo Medio (ERM) es definido como:
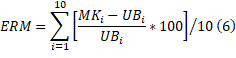
Donde 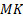 es la solución obtenida por nuestro algoritmo y
es la solución obtenida por nuestro algoritmo y 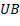 es el óptimo obtenido mediante la búsqueda exhaustiva.
es el óptimo obtenido mediante la búsqueda exhaustiva.
El AGHVNS fue implementado en Java y todas las ejecuciones fueron realizadas en un PC Pentium IV a 2.4 GHz con 1 GB de memoria RAM.
Una gran cantidad de ejecuciones revelaron que utilizar el número de generaciones del AGHVNS como condición de parada no era adecuado para controlar la convergencia del mismo. En muchos casos, el algoritmo alcanzó un óptimo local antes de completar la cantidad de generaciones. Como resultado, se introdujo un tiempo de procesamiento máximo el cual depende de la dimensión del problema a solucionar. El mismo fue arbitrariamente definido como 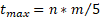 segundos, el cual, en términos computacionales, es un tiempo práctico y en todos los casos, permite al algoritmo culminar en un tiempo menor que definiendo como condición de parada el número de generaciones.
segundos, el cual, en términos computacionales, es un tiempo práctico y en todos los casos, permite al algoritmo culminar en un tiempo menor que definiendo como condición de parada el número de generaciones.
Los valores de los demás parámetros principales del AGHVNS son resumidos en la Tabla 1. Estos valores son tomados de (Fonseca et al., 2014)
Para ilustrar el problema que se soluciona en esta investigación se introduce un ejemplo de instancia. Esta describe un problema con 5 trabajos que deben ser procesados sobre 5 máquinas (5x5). Las tablas 2, 3, 4 y 5 muestran el tiempo de procesamiento de los trabajos sobre las máquinas, la fecha de liberación de cada una de las máquinas, los tiempos de configuración dependientes de la secuencia y los tiempos de transportación respectivamente.
| Trabajo/ Máquina | Tiempos de Procesamiento | ||||
|---|---|---|---|---|---|
| J 0 | J 1 | J 2 | J 3 | J 4 | |
| M0 | 10 | 6 | 11 | 8 | 11 |
| M1 | 15 | 9 | 14 | 10 | 14 |
| M2 | 12 | 11 | 9 | 10 | 6 |
| M3 | 8 | 4 | 8 | 9 | 12 |
| M4 | 6 | 6 | 8 | 6 | 3 |
| Máquina/Trabajo | Tiempos de Trasportación | ||||
| J 0 | J 1 | J 2 | J 3 | J 4 | |
| M 0 | 8 | 4 | 6 | 8 | 7 |
| M 1 | 7 | 8 | 8 | 5 | 7 |
| M 2 | 6 | 9 | 8 | 5 | 9 |
| M 3 | 6 | 5 | 4 | 7 | 6 |
La Tabla 2 es interpretada como el tiempo que necesita un trabajo en procesarse en cada una de las máquinas. Por ejemplo, el trabajo J0 necesita 10, 15, 8, 12 y 6 unidades de tiempo para procesarse en cada una de las 5 máquinas. Por su parte, la Tabla 3 muestra el tiempo que necesita cada máquina para ser liberada al comienzo de la planificación de la producción. En la Tabla 4 se detallan los tiempos de configuración dependiente de la secuencia. Esto significa, por ejemplo, que si la máquina M0 procesa al trabajo J0 y luego debe procesar al trabajo J1, necesitaría 2 unidades de tiempo para configurar la máquina antes de procesar a J1. Por último, en la Tabla 5 se muestran los tiempos de transportación de los trabajos desde una máquina hacia la otra. Por ejemplo, para trasladar el trabajo J0 desde la máquina M0 hacia la máquina M1, se necesitan 8 unidades de tiempo, de M1 hacia M2 se necesitan 7 unidades de tiempo y así sucesivamente. En la tabla solo se muestran los valores para las primeras cuatro máquinas debido a que en la última etapa (M5) el trabajo culmina su procesamiento.
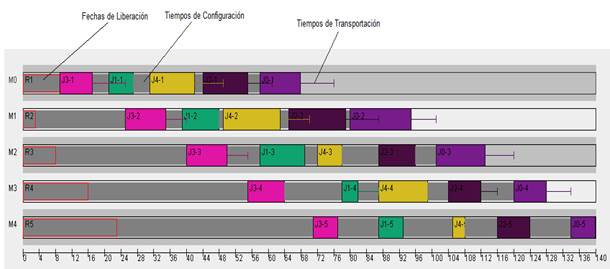
La Figura 6 muestra a través de un diagrama de Gantt la solución óptima al ejemplo planteado anteriormente donde el 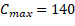 . En este son representadas las restricciones adicionales del problema planteado.
. En este son representadas las restricciones adicionales del problema planteado.
Como se mencionó anteriormente, dada la inexistencia de instancias del problema tratado en esta investigación, se generaron aleatoriamente instancias de diferentes tamaños de complejidad. Específicamente, se crearon 10 instancias (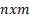 ) de 5x3, 5x4, 5x5, 7x6, 7x7, 8x8, 9x4, 9x9, 10x8 y 10x10, donde representa la cantidad de trabajos y la cantidad de máquinas respectivamente. El algoritmo propuesto fue ejecutado 10 veces para cada una de estas y el valor promedio de makespan
) de 5x3, 5x4, 5x5, 7x6, 7x7, 8x8, 9x4, 9x9, 10x8 y 10x10, donde representa la cantidad de trabajos y la cantidad de máquinas respectivamente. El algoritmo propuesto fue ejecutado 10 veces para cada una de estas y el valor promedio de makespan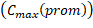 es calculado. Además, con el objetivo de analizar el rendimiento del algoritmo propuesto, el proceso de intensificación fue deshabilitado obteniendo un AG básico, el cual, al igual que el AGHVNS, fue ejecutado 10 veces por cada una de las instancias. Estos resultados se tomaron en cuenta para el estudio comparativo.
es calculado. Además, con el objetivo de analizar el rendimiento del algoritmo propuesto, el proceso de intensificación fue deshabilitado obteniendo un AG básico, el cual, al igual que el AGHVNS, fue ejecutado 10 veces por cada una de las instancias. Estos resultados se tomaron en cuenta para el estudio comparativo.
Asimismo, dado que estas instancias fueron generadas intencionalmente con un nivel de complejidad pequeño (dado por el número de trabajos y máquinas), se determinó el valor óptimo de para cada una de ellas realizando una búsqueda exhaustiva. El ERM fue calculado a partir de estos valores y los obtenidos por las dos variantes de AGs.
La Tabla 6 resume los resultados obtenidos. En esta se muestra además el menor valor de makespan (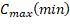 obtenido en las ejecuciones por ambas variantes. La última fila muestra el promedio de ERM.
obtenido en las ejecuciones por ambas variantes. La última fila muestra el promedio de ERM.
Basado en los resultados de la Tabla 6, se puede observar que el algoritmo propuesto es capaz de obtener buenos resultados y se muestra la aplicabilidad del mismo a problemas de scheduling; se tienen en cuenta restricciones que se presentan con frecuencia en entornos manufactureros reales. Los resultados corresponden con lo planteado en la literatura especializada si se tiene en cuenta la brecha que existe entre los problemas de programación de la producción que comúnmente se resuelven por los especialistas en el tema y los que se presentan en la práctica.
Para las 10 instancias propuestas, excepto para la instancia de 8x8, 10x8 y 10x10, el AGHVNS alcanzó el valor óptimo de makespan. Para las primeras cinco instancias, este logró el valor óptimo en todas sus ejecuciones. El promedio de ERM fue de solo un 0.0025%.
Además, el AG sin la fase de intensificación solo alcanzó el valor óptimo en las dos primeras instancias aunque para el resto, los valores obtenidos de makespan estuvieron cercanos a los óptimos. El promedio de ERM fue de 0.0209%.
Los resultados obtenidos en la tabla 6 muestran la importancia de lograr un balance entre la exploración y la explotación a partir de la fase de intensificación. Esta le permitió al algoritmo propuesto, en el proceso de búsqueda en ese espacio, alcanzar mejores soluciones que la variante de AG sin el proceso de búsqueda local. Esta afirmación es evidenciada al establecer una comparación entre los promedios de ERM entre el AGHVNS y el AG básico. El ERM del AGHVNS, en todos los casos, fue menor que el obtenido por el AG básico y este, a su vez, muy por debajo del 1%.
Este trabajo presentó la aplicación de un método híbrido para la solución del FSSP bajo el efecto de restricciones que se presentan en entornos reales de la producción. El algoritmo propuesto está constituido por tres componentes principales: una generación de la población inicial; un AG y un proceso de intensificación a través de una búsqueda local nombrada VNS. El AGHVNS fue evaluado a través de un conjunto de diez instancias de problemas y los resultados obtenidos fueron comparados con los valores óptimos y por los obtenidos mediante la variante básica del AG demostrando eficiencia y efectividad del mismo en cuanto a la calidad de las soluciones. Es importante mencionar que la metaheurística propuesta constituye una interesante alternativa para resolver problemas complejos de optimización. También se debe resaltar que el algoritmo propuesto es simple y fácil de implementar.
Se sugiere que un esquema más sofisticado de intensificación sea utilizado en el futuro. Esta decisión podría lograr un mejor balance entre la explotación y exploración de las soluciones. Igualmente, se propone incorporar otras restricciones como es el caso de máquinas paralelas no relacionadas, restricciones de precedencia y perturbaciones en las máquinas permitiendo modelar un entorno más realista de la producción. Esta extensión contribuiría aún más, a cerrar la brecha existente entre la teoría de scheduling y la aplicación en configuraciones industriales.