1. Introducción
El principal propósito de las tecnologías de asistencia es poder ayudar a mejorar la calidad de vida de
personas que sufren alguna discapacidad, disminuyendo de esta manera la dependencia que sienten debido a su incapacidad
motriz, la cual los lleva a percibir que son controlados por otras personas (
Kerstens et al., 2020).
De acuerdo con estimaciones del Ministerio de Salud y Protección Social de Colombia (
2019) para el 2019 existían 1 496 213 personas con alguna discapacidad, de los cuales el 37 % sufre de
alteraciones o limitaciones permanentes para usar su cuerpo, manos, brazos o piernas. Además, según los mismos estudios, el
80 % de las personas con discapacidad refirieron pertenecer a los estratos socioeconómicos uno y dos y, precisamente, su
discapacidad física es una limitante adicional para tener un empleo formal y estable. Por lo tanto, no solo existe una
demanda por tecnologías recientes o específicas para ayudar a personas discapacitadas, sino que el costo de tales
soluciones tecnológicas debe garantizar su accesibilidad (
Demby�s et al., 2019).
La robótica ha estado involucrada en diferentes aspectos de la tecnología de asistencia como la movilidad
personal, funciones sensoriales y de monitoreo (
Hassan, Abou-Loukh y Ibraheem, 2020), asistencia dentro de entornos controlados (
González et al., 2008), entre otros. Tradicionalmente, los robots se han enfocado en funciones de
automatización preprogramadas y en áreas de trabajo controladas (
Xu y Wang, 2021). Sin embargo, en los últimos años la robótica ha avanzado constantemente, creando de
esta manera robots más robustos con la capacidad de realizar acciones o tareas con una complejidad progresivamente mayor.
También se ha estado implementado algoritmos de inteligencia artificial (IA) para otorgarle a los robots autonomía y
adaptabilidad, las cuales son características fundamentales para su eventual implementación como tecnología de asistencia (
Li, et al., 2021).
Uno de los principales problemas de la autonomía en los robots es lograr identificar correctamente su
entorno y los objetos que lo rodean, ya sea para evitar colisiones, trazar trayectorias o simplemente para detectar objetos
(
Jardón, et al., 2008;
Huang, et al., 2020;
Miseikis et al., 2018). La técnica de visión computacional por triangulación matemática ha sido
bastante utilizada para solventar el problema de la autonomía. Sin embargo, esta técnica es susceptible a cambios de los
parámetros intrínsecos y extrínsecos de las cámaras, por lo que no se adapta muy bien a entornos dinámicos y, a la vez,
esta técnica necesita un modelo matemático a base de reglas para cumplir su objetivo que, en este caso, es la estimación de
las coordenadas de un objeto (
O�Mahony et al., 2020). Por otra parte, una red neuronal convolucional (CNN) es un tipo de red
artificial que intenta emular el ojo humano y la interpretación de imágenes que realiza el cerebro (
Ghosh, et al., 2020). Por tal motivo, esta técnica soluciona problemas relacionados a imágenes de forma
natural, utilizando principios de aprendizaje de neuronas orgánicas (
O�Mahony et al., 2020;
Smola y Vishwanathan, 2008), por lo que su uso, aplicación y resultados tienden a ser más orientados a
la interpretación nativa de las imágenes que realizan los seres humanos.
Estos campos están permitiendo a los robots adoptar la capacidad con la que los humanos y gran parte de
los animales interactúan con su entorno, mejorando y potencializando la teoría tradicional del control. Tal que se replican
mecanismos complejos de la biología como, por ejemplo, la visión estereoscópica, la cual es una forma biológica utilizada
para identificar profundidad y relieve en una imagen (
Valencia et al., 2016).
El aporte de esta investigación es la utilización de CNN para visión estereoscópica en un robot como
InMoov (
Langevin, 2012), el cual tiene cualidades físicas y funcionales equivalentes al del ser humano y que
puede ser utilizado para discernir la profundidad y localización de un objeto dentro de una escena. De manera que esta
funcionalidad es el cimiento de fases posteriores en esta investigación que le permitirán al robot InMoov localizar y
alcanzar un objeto que necesite una persona con discapacidad motriz que se encuentre dentro de un entorno doméstico.
2. Metodología
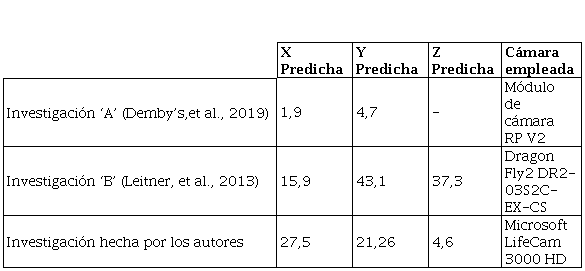
Con el objetivo de permitirle a la réplica del robot humanoide InMoov aprender la percepción espacial de
un entorno doméstico controlado, se desarrolló una arquitectura de redes neuronales convolucionales (CNN) para encontrar el
objeto, segmentarlo y estimar sus coordenadas cartesianas relativas (X, Y, Z) con respecto al robot, utilizando como punto
de partida las metodologías planteadas por Leitner, et al. (
2013) y Demby�s, et al. (
2019)
2.1. Robot humanoide InMoov
El algoritmo de percepción espacial se aplicó para darle esta funcionalidad a una réplica del proyecto del
robot humanoide de código abierto (
open source) InMoov. Las piezas se fabricaron a través de impresión 3D por FDM (modelado por deposición fundida) a
partir de los modelos 3D que se encuentran disponibles en la página oficial del proyecto InMoov (
Langevin, 2012).
En la
Figura 1 se esquematizan los sistemas de referencia del robot, de los cuales dos corresponden a las
cámaras del robot identificadas como LI �
Left Image� y RI �
Right Image�. Para la cabeza se determina también el sistema coordenado GR Body, el cual se usa como referencia para
la posición del objeto con respecto al robot.
Figura 1
Sistema de referencia de la cabeza de InMoov

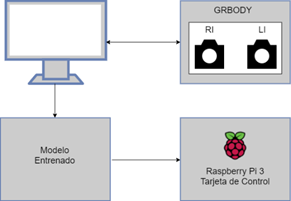
La captura inicial de las imágenes se realizó con las cámaras ubicadas en la cabeza del robot, las cuales
se enviaron a un computador personal por medio de USB, tal como se describe en la
Figura 2.
Aunque el robot tiene la capacidad de cambiar la orientación de las cámaras, así como girar su cabeza,
para este artículo se decidió mantener en una posición y orientación fija tanto las cámaras como la cabeza. Esto con el fin
de evaluar, primero, el desempeño de la red convolucional bajo estas condiciones para, posteriormente, analizar cuando la
orientación de la imagen cambia por movimientos de la cabeza y de las cámaras. La definición de los sistemas de referencias
está basada en el trabajo realizado por Valencia, et al. (
2016), lo cual se explica en detalle en la siguiente sección.
Figura 2
Esquema de control de la cabeza de InMoov
2.2. Visión estereoscópica
La visión estereoscópica es una herramienta utilizada en la robótica humanoide que tiene como fin darle
independencia a un sistema robótico a través de visión computacional por medio de dos cámaras desplazadas. Estas se
encargan de tomar la captura de dos imágenes, generar una triangulación geométrica y, finalmente, estimar la ubicación de
los objetos.
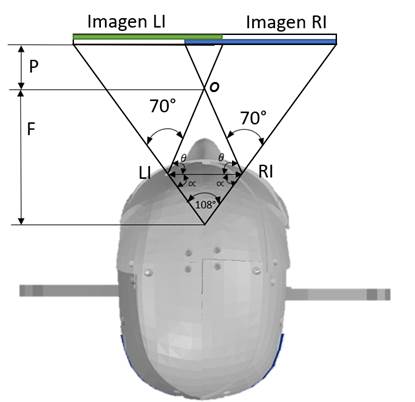
Esta técnica emplea dos cámaras ubicadas en cada uno de los ojos del robot InMoov. En la
Figura 3 se muestra el esquema geométrico proyectado desde la vista superior para la captura y
procesamiento de las imágenes de las cámaras. Esta figura contiene los parámetros fijos del sistema tales como: separación
entre cámaras LI y RI de 62.27 mm, rangos del campo de visión de las cámaras LI y RI en el eje X los cuales son de 70°,
restricciones determinadas por la distancia F al punto crítico de oclusión O de 107.167 mm, el cual está encargado de
definir el área limitante para el rastreo de objetos LI-O-RI y, finalmente, los ángulos ¸ = 73.8° y ü = 36.2, los cuales se
forman por la geometría generada con la posición de las cámaras, el campo de visión y F. Por último, P es la distancia
desde el punto de oclusión crítico y el objeto de interés (
Valencia, et al. 2016).
Estos datos fueron relevantes para el entorno controlado de trabajo, con el fin de deducir el área no
rastreable de un objeto formado por el triángulo LI-O-RI y de esa manera definir las dimensiones del entorno de
trabajo.
2.3. Redes neuronales convolucionales
La red neuronal convolucional o CNN por sus siglas en inglés (
Convolutional Neural Network) es un tipo de red neuronal artificial que tiene la capacidad de aprender
características, patrones o similitudes abstractas de objetos, escenas o cualquier información que esté en los datos de
entrada (
Qin, et al., 2018), los cuales, por lo general son, imágenes. Así que este tipo de red neuronal está
muy relacionada con la visión por computadora (
Wozniak, et al., 2018;
Li et al., 2019).
Una CNN consta de un conjunto finito de capas de convolución que se encargan de extraer características de
las imágenes. Tal que las primeras capas de convolución tendrán un nivel menor de abstracción, el cual irá aumentando con
relación a la cantidad de capas que existan (
Ghosh, et al., 2020). Por ejemplo, una CNN, para detectar un vaso, en las primeras capas aprenderá a
detectar características simples como líneas, bordes, colores, entre otros y, en las últimas capas, detectará
características o patrones complejos como siluetas, texturas, entre otros.
Figura 3
Sistema de referencia de los ojos
Posteriormente, para implementar la técnica por el método de visión estereoscópica es necesario realizar
la captura y el acondicionamiento de las imágenes del objeto detectado.
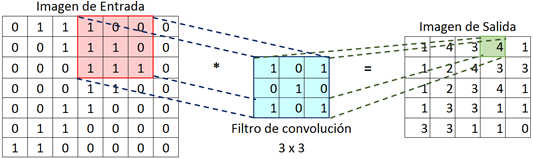
La extracción de información por cada capa de convolución se hace a través de filtros de un tamaño
inferior al tamaño de la imagen. Sin embargo, los tamaños más usados son 3x3, 5x5 y 7x7 (
Chansong y Supratid, 2021). Estos filtros recorren toda la imagen de izquierda a derecha y de arriba
hacia abajo, realizando un producto escalar con la matriz de píxeles de la imagen, con el fin generar una nueva imagen
convolucionada. La
Figura 4 es un ejemplo del funcionamiento del filtro de convolución 3x3 en una matriz de 7x7.
Figura 4
Ejemplo del proceso de convolución
La imagen de salida luego pasará por otro filtro llamado aplanamiento o
pooling, el cual se encarga de disminuir el tamaño espacial de la imagen con el fin de reducir la potencia
computacional requerida para procesar las matrices multidimensionales.
2.4. Transfer Learning
Como estrategia para estimar la posición del objeto, se utilizó
Transfer Learning, el cual consiste en tomar un modelo pre entrenado y adaptarlo con nuevos datos. El modelo
empleado es YoloV3 (
Redmon y Farhadi, 2018), el cual es una CNN que detecta y segmenta 80 clases de objetos distintos en
una caja. Si bien, este modelo es suficientemente robusto se escogió como clase única a detectar �vaso�, debido a que este
objeto reúne características geométricas simples para que la CNN de YoloV3 pueda aprender de manera más sencilla y,
también, porque este objeto es bastante utilizado por las personas en los entornos domésticos. Así que el robot solo podrá
detectar ese objeto de interés dentro la escena. Esto, se realizó de esta manera para que la CNN de percepción espacial
logre identificar correctamente el objeto y sus coordenadas. De manera que, la implementación de YoloV3 es el cimiento para
que el robot logré discernir el objeto de interés cuando esté rodeado por otros objetos.
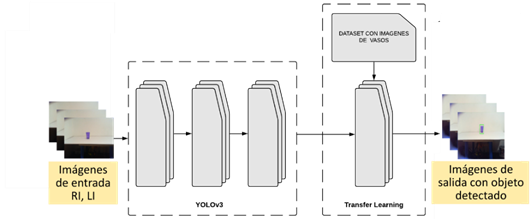
Por lo tanto, en la última capa de YoloV3 se anexa un Dataset con 1 000 imágenes diferentes de vasos y
etiquetados con la herramienta computacional LabelImg (
Tzutalin, 2015), con el fin de entrenar esa última capa. Finalmente, se pone a correr el modelo para
observar cómo detecta el objeto. La
Figura 5 muestra la adaptación de YoloV3 con las imágenes extraídas del robot InMoov y, así mismo, el
resultado luego de utilizar
Transfer Learning.
Figura 5
Arquitectura de algoritmo YoloV3 adaptada por Transfer Learning
Con las imágenes capturadas por el método de
Transfer Learning se construye el conjunto de datos para la CNN de percepción espacial, la cual se explica a
continuación junto con los parámetros y condiciones iniciales que se implementaron.
2.5. Conjunto de datos
Para facilitar el entrenamiento de una CNN se plantea adquirir los datos de imágenes estereoscópicas de un
entorno controlado, lo cual facilita la adaptación del conjunto de datos a la arquitectura planteada en una fase inicial y
después pretender su escalabilidad a entornos con perturbaciones.
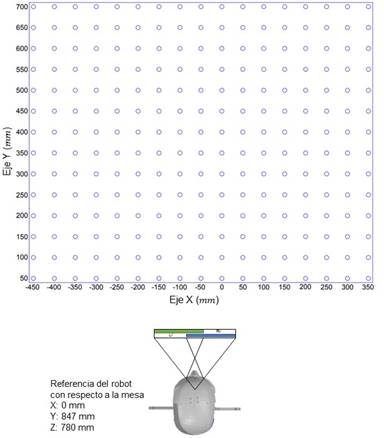
El entorno se realizó en una mesa con una cuadricula de puntos separados cada 50 mm a una distancia frente
al robot de 847mm, tal como se ve en la
Figura 6. Estos puntos sobre la mesa representan la posición que tomará el objeto dentro del escenario (
Demby�s, et al., 2019). Aparte de esto, la luminosidad dentro del entorno es constante.
Figura 6
Entorno controlado de recopilación de datos

La altura Z del robot es fija y la posición del objeto sobre la mesa en el eje X y Y varía en los puntos
designados de la cuadrícula, por lo que la variación en Z del escenario se realizó elevando la mesa 10 mm en 7 ocasiones
cada que el objeto recorriera todos los puntos de la cuadricula. La distribución de coordenadas sobre la mesa y la posición
del robot con respecto a la misma se evidencian en la
Figura 7. Para hallar la coordenada en X en el sistema de Coordenadas GR Body no es necesario hacer
alguna transformación en las medidas de la cuadricula, mientras que para los valores del eje Y se les suma una distancia de
840mm y en el eje Z se suma una distancia de 780mm. Estos valores representan la distancia del escenario con respecto a GR
Body.
Figura 7
Distribución de coordenadas sobre la mesa de entrenamiento
El método para recopilar el conjunto de entrenamiento de las imágenes de ambos ojos se realizó moviendo
manualmente el objeto en la escena y almacenando LI y RI con las coordenadas actuales del objeto en el sistema de
referencia GR Body como, por ejemplo [x_y_z.png].
Esta manera de nombrar las imágenes de entrenamiento fue extraída del conjunto de datos UTKFace (
Zhang, Song y Qi, 2017) que tiene la utilidad de simplificar el procesamiento de las imágenes y, a la
vez, correlacionar las etiquetas con las imágenes de una manera sencilla. Por otro lado, las imágenes se recopilaron con
una dimensión de (416 * 416 * 3)
pixeles, lo cual significa la anchura, altura y cantidad de canales RGB, correspondientemente. En la
Figura 8 se presenta un ejemplo de LI y RI.
Figura 8
Imagen captada por ambos ojos izquierdo y derecho respectivamente

De esta forma, se obtuvieron dos carpetas o directorios con 1 547 imágenes en cada uno. Ambas carpetas
tienen en común las coordenadas del objeto en las 1 547 posiciones, pero se diferencian en la distribución de pixeles
intrínsecos de las imágenes. Esto quiere decir que hay dos imágenes de entrada (izquierda y derecha) y 3 datos de salida
(X, Y, Z). Así que la arquitectura que se planteará en las próximas secciones es de tipo MIMO (
Multiple Input-Multiple Output).
La
Tabla 1 es una muestra de la cabecera del Dataframe, en él se encuentran las entradas y salidas del
sistema indexado y estructurado. Por otra parte, el Dataframe se dividió al 70 % para el entrenamiento y el 30 % restante
para validación y prueba del modelo. Esto, con el fin de verificar que los resultados obtenidos a través del aprendizaje no
estén sobre ajustados.
Tabla 1
Dataframe del conjunto de entrenamiento

Tanto para el preprocesamiento en las imágenes como en las coordenadas de la posición del vaso se hizo una
normalización al rango de 0 hasta 1, cambiando los valores de cada característica para que el valor mínimo sea 0 y luego
dividiendo por el valor máximo (
Geron, 2019b;
Smola y Vishwanathan, 2008).
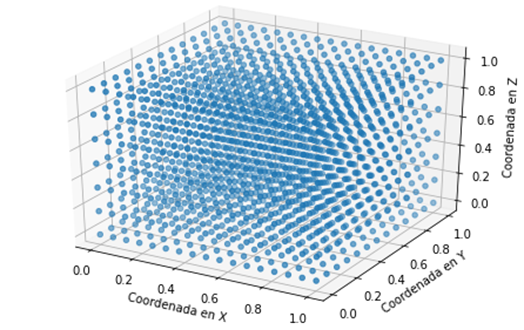
La
Figura 9 es una representación tridimensional del conjunto de entrenamiento normalizado. Por otro lado,
no se utilizó el aumento de datos enfocado en las imágenes (
Lee y Saitoh, 2018) para no modificar su estructura interna y la organización de pixeles que contienen
cada una de las imágenes, ya que al modificarlo el valor recopilado de la coordenada en dicha imagen no tendría coherencia
con el valor real de la coordenada.
Figura 9
Dataset de las coordenadas de entrenamiento normalizado
2.6. Arquitectura CNN de percepción espacial
La arquitectura CNN de percepción espacial utilizada en esta investigación se basa en UTKFace (
Zhang, Song y Qi, 2017), la cual tiene como característica principal distinguir entre 3 etiquetas
(edad, genero, raza). Y en la arquitectura propuesta por Radu Enuc� (
2019), la cual recibe dos imágenes de espectrogramas (corriente y voltaje) para predecir entre 11
etiquetas útiles. Por lo tanto, se extrajeron las particularidades de estas dos arquitecturas y se interpolaron al enfoque
de esta investigación.
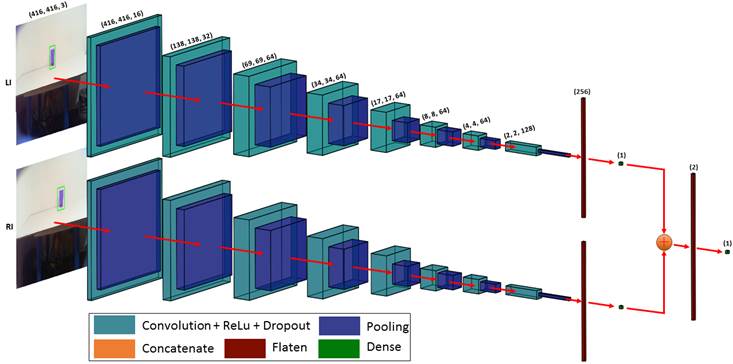
La
Figura 10 es una representación simplificada de la arquitectura diseñada, en la cual se ilustra
únicamente una sola coordenada para fines demostrativos. La arquitectura es una red neuronal convolucional supervisada, tal
que consta de dos canales principales correspondientes a LI y RI, los cuales son las imágenes de entrada. Cada canal se
divide en tres ramas (X, Y, Z) que son las etiquetas o datos de entrenamiento. De esta manera, la CNN aprende
características, similitudes y patrones únicos de cada imagen y coordenada por separado con el fin de que, en capas
posteriores, se concatene la información que ha aprendido de cada coordenada por separado con su igual de la otra imagen.
Esto quiere decir que toda la arquitectura es una sola CNN, por lo que el entrenamiento de cada rama en cada canal se hace
de manera paralela. De igual forma, el método que se usó para calcular el gradiente de la función de error con respecto a
todos los pesos de la red fue Backpropagation (
Lillicrap, et al., 2020).
Figura 10
Arquitectura propuesta de dos canales, una rama. La salida es una sola coordenada.
Las convoluciones de la capa oculta usan un filtro estándar de tamaño 3x3 que recorre toda la imagen y la
minimiza a lo alto y a lo largo, pero aumenta su profundidad. Mientras que el filtro que usa el
pooling para agrupar y reducir el tamaño de la imagen es de 2x2.
Luego de cada convolución se utiliza la técnica de regularización
Dropout para disminuir el sobreajuste de la CNN una vez que entrene (
Poernomo y Kang, 2018), omitiendo aleatoriamente por cada capa oculta el 25 % de las neuronas. Por
último, cada neurona de esta capa utiliza una función de activación tipo ReLu, la cual anula los valores negativos y deja
intacto los valores positivos de cada neurona.
La activación que se utiliza en las capas densas es de tipo lineal con el fin de obtener un resultado
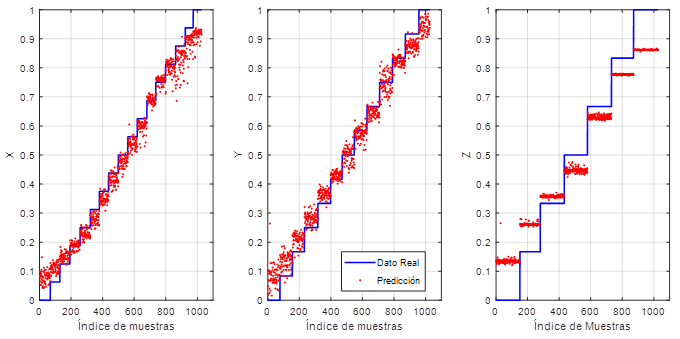
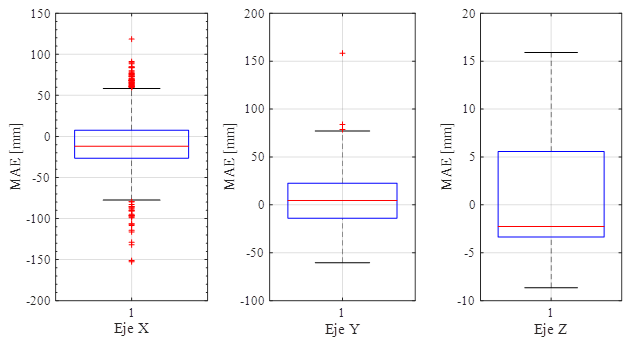
numérico análogo a la salida, por lo tanto, esto indica que el modelo planteado es de regresión lineal. La métrica usada
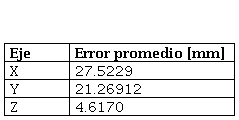
para la medición del error en el entrenamiento y validación de la CNN fue MAE (
Mean Absolute Error). La Ecuación 3 es la métrica que halla el promedio de la diferencia absoluta entre el valor
esperado y el valor predicho por el modelo. La ventaja de utilizar este tipo de métrica en comparación con MSE (
Mean Square Error) es que mejora la precisión del modelo en términos del error promedio, siempre y cuando los datos
de entrada no presenten mucho ruido (
Qi, et al., 2020).
2.7. Experimentos
Los valores de los parámetros utilizados en el entrenamiento se asignaron de manera heurística con un
total de 23 ensayos al entrenar la red neuronal. La cantidad de neuronas asignadas a las capas de la CNN de percepción
espacial
Mientras que la tasa de aprendizaje o LR por sus siglas en inglés (
Learning Rate) puede tomar el rango de valores presentados en la Ecuación 5 para que converja el algoritmo del
descenso del gradiente a un mínimo global en cada una de las coordenadas.
Sin embargo, el valor que arrojaron los resultados expuestos en la siguiente sección fue lr = 9.6 e -4
Por otro lado, se utilizó el descenso del gradiente por mini-lote a 32 (
Khirirat, Feyzmahdavian y Johansson, 2017), lo cual significa que se tomarán esas cantidades de
muestras por cada iteración de entrenamiento. Por último, todo el entrenamiento se hizo con un total de 100 épocas.
2.8. Plataforma experimental
La plataforma experimental desarrollada consta de una cabeza robótica de InMoov junto con dos cámaras
internas de referencia Microsoft LifeCam HD- 3000 con una resolución máxima para la captura de fotos de 1 280 x 720 píxeles
y una distancia focal de 140 mm. Estas cámaras se encuentran ubicadas en los ojos del robot tal como se describe en la
Figura 1 y
Figura 3.
Además, tanto la programación y el entrenamiento de la CNN de percepción espacial se realizó usando el
servicio en la nube Google Colaboratory con los
frameworks de Tensorflow y Keras para Python. El servidor remoto para el entrenamiento fue una GPU Nvidia Tesla P100
PCle, la cual tiene 16 GB de VRAM. Mientras que el modelo entrenado se migró para correrlo, finalmente, en un Raspberry Pi
3 de 1Gb de RAM, usando Tensorflow Lite. El video de las cámaras se transfiere a la red neuronal usando OpenCV.